垃圾回收算法梳理
1. 如何计算对象已死
1.1 引用计数器算法
引用计数器算法是给每个对象设置一个计数器,当有地方引用这个对象的时候,计数器+1,当引用失效的时候,计数器-1,当计数器为0的时候,JVM就认为对象不再被使用,是“垃圾”了。
引用计数器实现简单,效率高;但是不能解决循环引用问问题(A对象引用B对象,B对象又引用A对象,但是A,B对象已不被任何其他对象引用),同时每次计数器的增加和减少都带来了很多额外的开销,所以在JDK1.1之后,这个算法已经不再使用了。
1.2 可达性分析算法
可达性分析算法是通过一些“GC Roots”对象作为起点,从这些节点开始往下搜索,搜索通过的路径成为引用链(Reference Chain),当一个对象没有被GC Roots的引用链连接的时候,说明这个对象是不可用的,如下图所示。

GC Roots对象包括:
虚拟机栈(栈帧中的本地变量表)中的引用的对象。
方法区域中的类静态属性引用的对象。
方法区域中常量引用的对象。
本地方法栈中JNI(Native方法)的引用的对象。
上面只是标记了对象是否可以被回收,实际上在java中首先会标记下对象,会调用对象里面的
protected void finalize()这个方法,这个时候对象还有救,只要在这个方法把该对象和引用链对接上,其实可以逃脱被回收
2. 回收的区域
- 新生代
- 永久代
新生代,这个很容易理解,一般来说永久带是最不好回收的。永久代主要回收以下部分内容:
- 废弃常量
- 无用的类
3. 垃圾回收算法
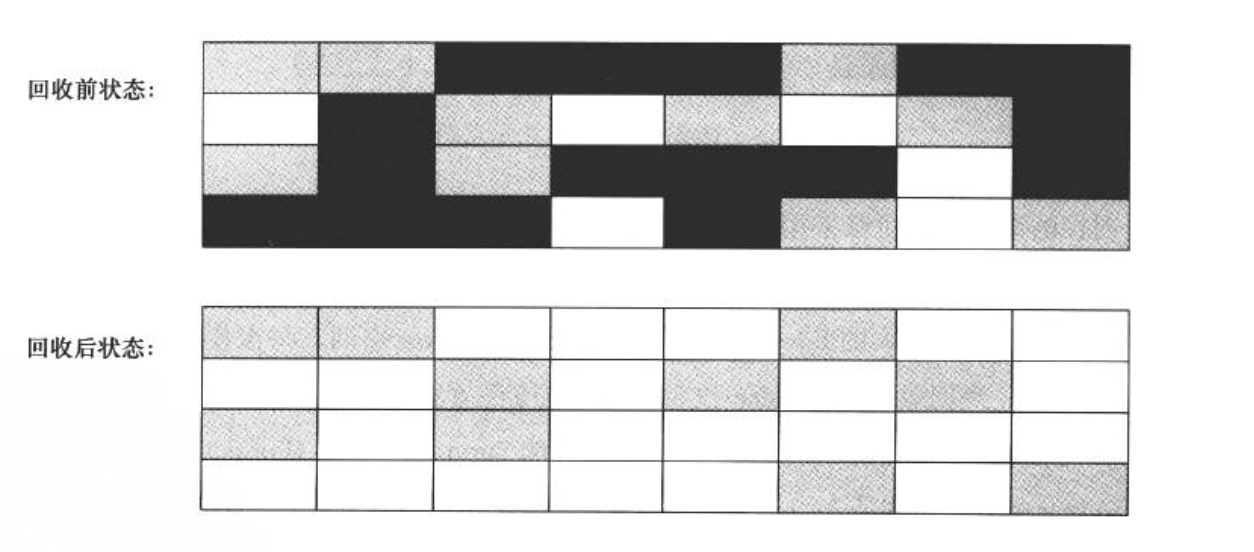
3.1 标记—清除算法
标记—清除算法包括两个阶段:“标记”和“清除”。在标记阶段,确定所有要回收的对象,并做标记。清除阶段紧随标记阶段,将标记阶段确定不可用的对象清除。
标记—清除算法是基础的收集算法,标记和清除阶段的效率不高,而且清除后回产生大量的不连续空间,这样当程序需要分配大内存对象时,可能无法找到足够的连续空间。如下图所示:
3.2 复制算法
复制算法是把内存分成大小相等的两块,每次使用其中一块,当垃圾回收的时候,把存活的对象复制到另一块上,然后把这块内存整个清理掉。这种方式听上去确实是非常不错的方案,但是总的来说对内存的消耗十分高。
复制算法实现简单,运行效率高,但是由于每次只能使用其中的一半,造成内存的利用率不高。现在的JVM用复制方法收集新生代,由于新生代中大部分对象(98%)都是朝生夕死的,所以两块内存的比例不是1:1(大概是8:1),也就是常提到的一块Eden(80%)和两块Survivor(20%)。当然也会存在10%不够用的情况,这个后面在进行梳理,会有一个补偿机制,也就是分配担保

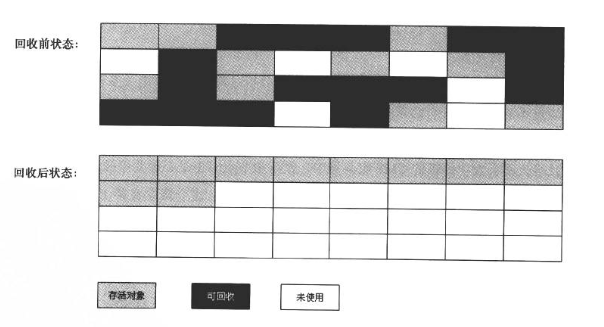
3.3 标记—整理算法
复制收集算法会存在一种极端情况,就是对象都没死。这种情况会在老年代有几率的出现,所以根据老年代的特点提出了标记—整理算法。 标记—整理算法和标记—清除算法一样,但是标记—整理算法不是把存活对象复制到另一块内存,而是把存活对象往内存的一端移动,然后直接回收边界以外的内存,如下图所示:
3.4 分代收集
分代收集是根据对象的存活时间把内存分为新生代和老年代,根据个代对象的存活特点,每个代采用不同的垃圾回收算法。新生代采用标记—复制算法,老年代采用标记—整理算法。
垃圾算法的实现涉及大量的程序细节,而且不同的虚拟机平台实现的方法也各不相同。上面介绍的只不过是基本思想。