简单使用和配置
这里主要是与spring的集成,让spring去管理Elasticsearch,Spring通过ElasticsearchTemplate对Elasticsearch进行封装,简化了一些增删改查的操作。配置如下:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:elasticsearch="http://www.springframework.org/schema/data/elasticsearch"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/data/elasticsearch http://www.springframework.org/schema/data/elasticsearch/spring-elasticsearch.xsd">
<elasticsearch:repositories base-package="com.es.main.repository"
/>
<elasticsearch:transport-client id="client"
cluster-nodes="192.168.114.109:9300,192.168.114.109:9300"
cluster-name="searches"
/>
<bean name="elasticsearchTemplate" class="org.springframework.data.elasticsearch.core.ElasticsearchTemplate">
<constructor-arg name="client" ref="client"/>
</bean >
</beans>
上面配置主要进行了三个配置:
- 指定仓库包名
- 链接client,多个nodes可以通过逗号进行分割。并且指定cluster-name,这个是对外提供的集群的名称。可以通过Elasticsearch的命令进行查看集群名称,一般默认名称是
elasticsearch - 配置ElasticsearchTemplate,这个封装了elasticsearch client的操作,同时也可以通过
ElasticsearchTemplate获取elasticsearch client
<elasticsearch:repositories base-package="com.es.main.repository"/>详细参数介绍如下:
| Name | 描述 |
|---|---|
| base-package | Defines the package to be used to be scanned for repository interfaces extending Repository (actual interface is determined by specific Spring Data module) in auto detection mode. All packages below the configured package will be scanned, too. Wildcards are allowed.(简单的来说主要是扫描继承了Repository接口的类,比如ElasticsearchRepository、ElasticsearchCrudRepository等,然后通过代理自动的去实现接口) |
| repository-impl-postfix | Defines the postfix to autodetect custom repository implementations. Classes whose names end with the configured postfix will be considered as candidates. Defaults to Impl. (Repository接口定义可以进行实现,repository-impl-postfix主要配置具体实现类的后缀,比如ArticleRepositoryImpl,默认是Impl结尾) |
| query-lookup-strategy | Determines the strategy to be used to create finder queries. See Query lookup strategies for details. Defaults to create-if-not-found. (定义创建查询的模式,大概有三种模式CREATE_IF_NOT_FOUND(默认模式,先搜索用户声明的,不存在则自动构建)、USE_DECLARED_QUERY(用户声明查询)、CREATE(按照接口名称自动构建查询)) |
| named-queries-location | Defines the location to look for a Properties file containing externally defined queries.named SQL存放的位置,默认为META-INF/jpa-named-queries.properties |
| consider-nested-repositories | Controls whether nested repository interface definitions should be considered. Defaults to false. (是否考虑 内部 接口的定义,默认是false。不处理内部接口) |
<elasticsearch:transport-client/> 详细参数配置如下:
| name | 描述 |
|---|---|
| id | 定义client名称 |
| client-transport-ping-timeout | The time to wait for a ping response from a node. Defaults to 5s.(定义ping的超时) |
| client-transport-ignore-cluster-name | Set to true to ignore cluster name validation of connected nodes. (定义忽略clustername) |
| client-transport-nodes-sampler-interval | How often to sample / ping the nodes listed and connected. Defaults to 5s. 多少秒进行ping一次 |
| client-transport-sniff | 设置client.transport.sniff为true来使客户端去嗅探整个集群的状态,把集群中其它机器的ip地址加到客户端中,这样做的好处是一般你不用手动设置集群里所有集群的ip到连接客户端,它会自动帮你添加,并且自动发现新加入集群的机器。 |
| cluster-nodes | 定义cluster节点集合 |
| cluster-name | 集群名称 |
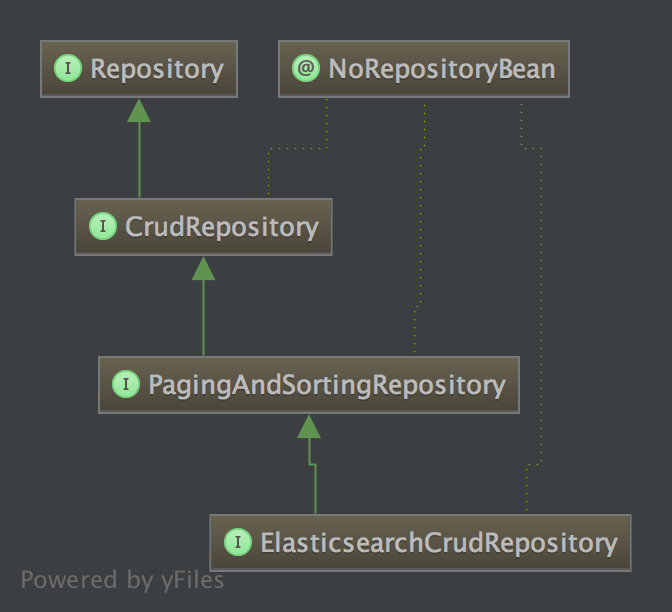
@Repository 是Spring原生注解,而ElasticsearchRepository集成了Spring Data JPA的一些操作,完全可以通过方法名称去查询,同时
ElasticsearchRepository还具备一些分页和增删改查功能,具体继承接口如下:
package com.es.main.repository;
import com.es.main.domain.Article;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface ArticleRepository extends ElasticsearchRepository<Article, Integer> {
}
具体的bean,@Document 指定索引名称,@Id指定了主键,主要用来区分数据和更新数据的时候使用,如果@Id声明的字段有相同的值,那么就会认为是一条数据,通过@Field来指定数据的type,是否被索引和评分。当然Spring Data Elasticsearch还有其他注解,后面的文章会继续讲解。
@Document(indexName = "coffee_test")
public class Article {
@Id
private int id;
@Field(type = FieldType.String, index = FieldIndex.analyzed, store = true)
private String content;
@Field(type = FieldType.String, index = FieldIndex.not_analyzed, store = false)
private String title;
@Field(type = FieldType.Date, index = FieldIndex.not_analyzed, store = true)
private Date updateDate;
}
使用方式十分简单,很好的减少了原生api的代码量,基本跟hibernate和jpa的使用方式差不多,具体如下:
public static void main(String args[]) throws IOException, NoSuchMethodException {
ClassPathXmlApplicationContext classPathXmlApplicationContext = new ClassPathXmlApplicationContext("spring-es.xml");
ElasticsearchTemplate elasticsearchTemplate = (ElasticsearchTemplate) classPathXmlApplicationContext.getBean("elasticsearchTemplate");
ArticleRepository articleRepository = classPathXmlApplicationContext.getBean(ArticleRepository.class);
Article article = new Article();
article.setContent("我是中国人,我不是日本人");
article.setTitle("我是标题");
article.setId(133);
//保存数据到esearch中
articleRepository.save(article);
Page<Article> page = articleRepository.search(new NativeSearchQueryBuilder()
.withQuery(termQuery("content", "我是中国"))
.build());
}